En 2010, un bug en el gestor de paquetes de Fedora hacía que yum consumiera memoria de forma descontrolada durante actualizaciones largas. El OOM Killer, siguiendo su lógica impecable, decidía terminar el proceso con mayor puntuación en ese momento: el propio yum. La actualización quedaba a medias, los paquetes en estado inconsistente y el sistema a veces inutilizable. No fue un fallo del kernel. Fue un fallo de no haber configurado ningún límite. El kernel hizo exactamente lo que tenía que hacer.
El OOM Killer —Out Of Memory Killer, el mecanismo del kernel de Linux que termina procesos cuando la memoria se agota— es una de esas piezas de infraestructura que nadie quiere ver en acción. Cuando aparece, significa que algo ha fallado antes: la planificación de capacidad, la configuración de límites, la monitorización o todo a la vez. Y aunque su existencia es necesaria, su comportamiento puede resultar desconcertante si no se entiende cómo toma decisiones.
Este artículo explora cómo funciona el OOM Killer, qué papel juega el swap en todo esto, cómo diagnosticar situaciones de presión de memoria antes de que el kernel tenga que intervenir, y qué herramientas concretas permiten influir en sus decisiones.
Cómo decide el kernel a quién matar
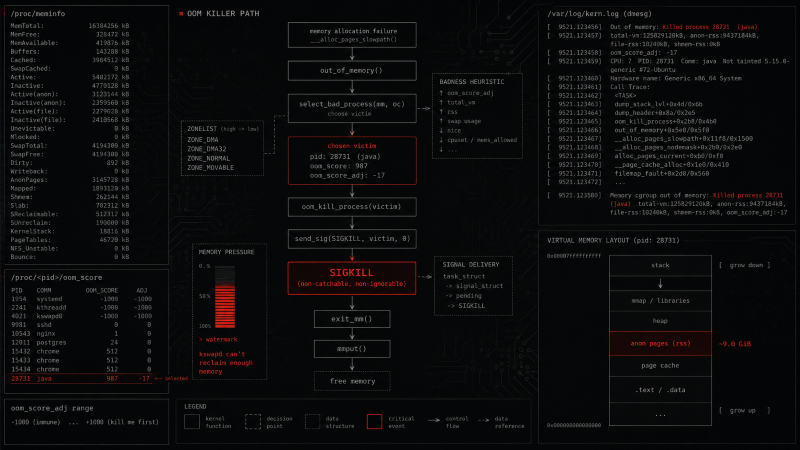
El OOM Killer no es caprichoso. Cuando el kernel detecta que no puede satisfacer una petición de memoria y que no hay más opciones, activa un algoritmo que evalúa todos los procesos en ejecución y les asigna una puntuación (oom_score). El proceso con la puntuación más alta es el elegido.
La puntuación se calcula principalmente en función de cuánta memoria consume el proceso en relación con la memoria total del sistema. A eso se suman ajustes según tiempo en ejecución y ciertos flags del proceso: los que tienen capacidades elevadas como CAP_SYS_ADMIN reciben algo de protección, pero no es automática ni garantizada para todos los procesos del sistema. La lógica intenta ser razonable: matar lo que más memoria consume, preservar lo que parece crítico para la estabilidad.
Pero «razonable» no significa «predecible» en un entorno de producción. Un contenedor que acaba de arrancar y está consumiendo memoria rápidamente puede tener una puntuación más alta que un servicio estable que lleva días funcionando. El OOM Killer no sabe qué proceso es crítico para el negocio. Solo sabe qué proceso consume más memoria en ese momento.
Ver la puntuación de un proceso
bash
# Puntuación calculada por el kernel (0-1000, mayor = más probable de morir)
cat /proc/<PID>/oom_score
# Ajuste manual actual (-1000 a +1000)
cat /proc/<PID>/oom_score_adj
# Ejemplo con el PID de nginx
cat /proc/$(pgrep nginx | head -1)/oom_scoreConfirmar que el OOM Killer ha actuado
Cuando el kernel mata un proceso, queda registrado. Esto es lo primero que hay que mirar ante un proceso desaparecido sin causa aparente:
bash
# En el ring buffer del kernel (más reciente primero)
dmesg | grep -i "oom\|killed process\|out of memory"
# Vía journalctl, más cómodo para filtrar por fecha
journalctl -k --since "2 hours ago" | grep -i oom
# Buscar en logs del sistema si no usas journald
grep -i "out of memory\|oom.kill" /var/log/kern.log
grep -i "out of memory\|oom.kill" /var/log/messagesLa salida típica tiene esta pinta:
kernel: Out of memory: Killed process 14872 (java) total-vm:4194304kB, anon-rss:3145728kB
kernel: oom_reaper: reaped process 14872 (java), now anon-rss:0kBAhí tienes el PID, el nombre del proceso y cuánta memoria estaba usando en el momento de la ejecución.
Controlar qué procesos sobreviven: oom_score_adj
Linux permite modificar la puntuación de un proceso mediante oom_score_adj, con un rango de -1000 a +1000. Un valor de -1000 hace que el proceso sea prácticamente intocable. Un valor de +1000 lo convierte en el primero de la lista.
bash
# Proteger un proceso crítico (menos probable de ser matado)
echo -500 > /proc/<PID>/oom_score_adj
# Sacrificar un proceso no crítico (más probable de ser matado)
echo 500 > /proc/<PID>/oom_score_adj
# Hacer un proceso prácticamente inmune
echo -1000 > /proc/<PID>/oom_score_adjEste ajuste es volátil: desaparece cuando el proceso termina. Para aplicarlo de forma persistente en servicios gestionados por systemd, la forma correcta es usar la directiva OOMScoreAdjust en la unit.
ini
# /etc/systemd/system/mi-servicio.service
[Service]
OOMScoreAdjust=-900Después de modificar la unit:
bash
systemctl daemon-reload
systemctl restart mi-servicioUna advertencia importante: si se marca todo como crítico, la protección pierde todo su sentido. El kernel seguirá necesitando matar algo, y simplemente elegirá el menos protegido de los «críticos». Usa esta herramienta con criterio.
El papel del swap: amortiguador o problema
El swap ha sido durante décadas una pieza estándar de cualquier sistema Unix. La idea es simple: cuando la RAM se agota, el kernel puede mover páginas de memoria poco usadas al disco, liberando RAM para procesos activos. En teoría, esto evita que el sistema se quede sin memoria. En la práctica, el swap puede convertirse en un problema mayor que el que intenta resolver.
Cuando un sistema empieza a hacer swap intensivo, el rendimiento se desploma. Incluso un SSD rápido tiene latencias de acceso entre 100 y 1.000 veces peores que la RAM. En entornos cloud con almacenamiento en red —EBS en AWS, Persistent Disk en GCP— la situación puede ser catastrófica: el swap se convierte en operaciones de red con latencias variables, y un sistema en thrashing puede tardar minutos en responder a cualquier cosa. El sistema no cae, pero está efectivamente muerto.
Un proceso que necesita acceder a memoria que está en swap se bloquea esperando que el kernel la traiga de vuelta. Si muchos procesos están en esa situación simultáneamente, el sistema entra en thrashing: pasa más tiempo moviendo páginas entre RAM y disco que ejecutando trabajo útil.
Ver el uso de swap y la presión de memoria
bash
# Visión rápida: la columna "available" es lo que importa, no "free"
free -h
# Desglose detallado desde /proc
cat /proc/meminfo | grep -E "MemTotal|MemFree|MemAvailable|SwapTotal|SwapFree|SwapCached"
# Actividad de swap en tiempo real (si si/so suben, hay problema)
vmstat 2 10
# Procesos que más memoria consumen en este momento
ps aux --sort=-%mem | head -15La distinción entre memoria libre y memoria disponible es crítica. Linux usa la memoria libre como caché de disco para mejorar el rendimiento, lo que hace que la columna free parezca casi siempre baja. Ver poca memoria libre es completamente normal. Ver poca memoria available significa que el kernel ya ha liberado toda la caché y empieza a quedarse sin opciones reales.
Ajustar swappiness
El parámetro swappiness controla la tendencia del kernel a mover páginas al swap frente a liberar caché de página. Su rango es de 0 a 200 en kernels recientes (anteriormente hasta 100).
bash
# Ver valor actual (60 es el valor por defecto en la mayoría de distros)
cat /proc/sys/vm/swappiness
# Cambiar en caliente (sin reinicio)
sysctl -w vm.swappiness=10
# Hacer el cambio permanente
echo "vm.swappiness=10" >> /etc/sysctl.conf
sysctl -pUn valor bajo (10–20) hace que el kernel prefiera liberar caché antes que mover procesos al swap. Para servidores de base de datos o servicios con latencia crítica, valores bajos son habituales. Para sistemas de escritorio o entornos donde la hibernación es relevante, valores más altos tienen sentido.
Sobre el tamaño del swap: no existe una fórmula universal. La regla antigua de «el doble de la RAM» viene de una época en que los sistemas tenían 128 MB. En servidores modernos con decenas o cientos de GB de RAM, un swap enorme no soluciona un problema de capacidad, solo retrasa el colapso. En nodos de Kubernetes, muchos equipos van directamente a swap desactivado, prefiriendo que el OOM Killer local del contenedor actúe rápido antes que dejar al nodo degradarse. En servidores físicos con cargas mixtas, algo de swap puede actuar como amortiguador para procesos auxiliares que apenas se usan. La decisión depende del tipo de carga, la tolerancia a la latencia y la capacidad de recuperación ante fallos.
Presión de memoria con cgroup v2
En sistemas modernos con cgroup v2, hay una métrica más refinada que el porcentaje de uso: la presión de memoria, que indica cuánto tiempo están esperando los procesos por memoria.
bash
# Presión de memoria a nivel de sistema
cat /proc/pressure/memory
# Presión de un cgroup específico
cat /sys/fs/cgroup/<nombre-del-grupo>/memory.pressureLa salida tiene tres líneas (some, full, avg10/avg60/avg300). Cuando some empieza a subir de forma sostenida, los procesos están esperando memoria. Cuando full es distinto de cero, el sistema ya no puede progresar. Es una señal más temprana y precisa que el porcentaje de swap usado. La documentación oficial está en kernel.org/doc/html/latest/admin-guide/cgroup-v2.html.
Contenedores: OOM Killer local y límites de memoria
En entornos con contenedores, la dinámica cambia. Sin límites de memoria definidos, un contenedor puede consumir toda la RAM disponible en el nodo, forzando al OOM Killer del sistema operativo a actuar sobre cualquier proceso del nodo, no solo sobre el contenedor problemático. Con límites bien definidos, el contenedor tiene su propio OOM Killer local que actúa antes de que el problema escale.
Límites en Docker
bash
# Limitar memoria RAM y deshabilitar swap para el contenedor
docker run --memory="512m" --memory-swap="512m" mi-imagen
# --memory-swap igual a --memory significa swap = 0 para ese contenedor
# Para ver los límites de un contenedor en ejecución:
docker inspect <container_id> | grep -i memoryLímites en Kubernetes
yaml
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"Sin limits.memory, el pod puede consumir memoria sin techo hasta que el OOM Killer del nodo intervenga. Con límites, el OOM Killer actúa a nivel de pod antes de que el nodo se vea afectado.
Señales de que algo va mal (antes de que el kernel actúe)
El OOM Killer no aparece de la nada. Hay señales claras de que el sistema está bajo presión de memoria que aparecen antes de que el kernel decida terminar algo. El problema es que esas señales no siempre se monitorizan o se interpretan correctamente.
Memoria disponible cayendo: cuando MemAvailable en /proc/meminfo cae por debajo del 10–15% de la RAM total, el sistema empieza a estar en zona de riesgo. Por debajo del 5%, el OOM Killer puede activarse en cualquier momento.
Swap creciendo de forma sostenida: un uso bajo y estable de swap no es preocupante. Un crecimiento rápido o un swap que se llena por completo indica que el sistema está intentando liberar RAM desesperadamente.
Tasa de intercambio de páginas elevada: en la salida de vmstat, las columnas si (swap in) y so (swap out) deben ser cero o casi cero en condiciones normales. Si empiezan a subir de forma consistente, el thrashing ya está comenzando.
Logs del kernel con advertencias previas: antes de activar el OOM Killer, el kernel suele registrar advertencias sobre memoria baja. Son una oportunidad para actuar antes de que algo crítico muera, pero solo si alguien está mirando. Herramientas como dmesg -w en una terminal o alertas sobre patrones en /var/log/kern.log pueden ayudar.
Procesos descontrolados: la causa más común
Un proceso con un leak de memoria que nadie ha detectado es la causa más frecuente de que el OOM Killer tenga que actuar. Un proceso sin límites que crece indefinidamente eventualmente agotará la RAM del sistema.
Para detectarlos antes de que provoquen un OOM:
bash
# Ver crecimiento de memoria de un proceso a lo largo del tiempo
watch -n 5 'ps aux --sort=-%mem | head -10'
# Uso de memoria por proceso con detalle de RSS y VSZ
ps -eo pid,ppid,cmd,%mem,rss --sort=-%mem | head -20
# Monitorizar un proceso específico cada 10 segundos
while true; do
ps -p <PID> -o pid,rss,vsz,cmd
sleep 10
doneTambién puedes usar stress para simular presión de memoria en un entorno controlado y validar que tus alertas y límites funcionan antes de que lo haga el OOM Killer en producción.
Errores comunes que empeoran la situación
Añadir más swap para «solucionar» falta de memoria. El swap no es una extensión de la RAM. Es un amortiguador de último recurso. Si el sistema está usando swap de forma intensa, el problema es de capacidad, y añadir más swap solo retrasa el colapso convirtiendo el problema de memoria en un problema de rendimiento catastrófico.
No establecer límites en contenedores porque «nunca ha habido problemas». Un leak de memoria en un proceso sin límites puede tumbar un nodo entero y afectar a todos los contenedores que corren en él. Un leak en un proceso con límites bien definidos solo afecta a ese contenedor.
Ignorar las advertencias del kernel sobre memoria baja. Esas líneas en los logs no son informativas, son preventivas. Cuando aparecen, el sistema ya está en una situación delicada. Actuar en ese momento puede evitar que el OOM Killer tenga que tomar decisiones por ti.
Confiar en que el OOM Killer siempre elegirá el proceso correcto. El algoritmo es razonable, pero no infalible ni consciente del negocio. Sin ajustes manuales en oom_score_adj y sin límites claros, puede terminar el proceso equivocado en el peor momento posible.
Marcar todos los procesos como críticos con oom_score_adj=-1000. Si todo es prioritario, nada lo es. El kernel seguirá necesitando matar algo, y simplemente elegirá el menos protegido del grupo de «intocables».
Estrategia de defensa en resumen
La mejor defensa contra el OOM Killer es no llegar a necesitarlo. Eso implica planificar la capacidad de memoria con realismo, establecer límites claros para procesos y contenedores, y monitorizar el uso real de memoria en producción con alertas basadas en MemAvailable, no en MemFree.
Para sistemas físicos o VMs con cargas estables, un swappiness bajo (10–20) y algo de swap como amortiguador para procesos auxiliares puede tener sentido. Para nodos de Kubernetes o contenedores efímeros, la tendencia actual es swap a cero con límites bien definidos por pod.
Para servicios críticos que no pueden permitirse ser terminados, OOMScoreAdjust en la unit de systemd es la forma correcta y persistente de protegerlos. Pero siempre combinado con límites y alertas: la protección de un proceso sin límites claros simplemente transfiere el problema a otro proceso del sistema.
El OOM Killer es un mecanismo de último recurso. Su existencia es necesaria porque los sistemas reales tienen límites físicos y los errores de software existen. Pero llegar a activarlo es siempre un fallo de planificación, monitorización o configuración. La clave no es eliminar el riesgo por completo, sino construir sistemas que detecten problemas de memoria antes de que el kernel tenga que intervenir.
Porque cuando el OOM Killer actúa, el proceso ya está muerto. Lo único que queda es entender qué falló y asegurarse de que no vuelva a pasar.
Para seguir aprendiendo
- Systems Performance: Enterprise and the Cloud — Brendan Gregg, 2ª ed., Addison-Wesley (2020) — La referencia canónica para análisis de rendimiento en Linux. El capítulo de memoria cubre OOM, swap, herramientas de profiling y entornos cloud. La segunda edición incluye contenedores y Kubernetes, que la primera no contemplaba.
- Documentación del kernel: gestión de memoria — Explica el modelo de memoria virtual, el algoritmo del OOM Killer y todos los parámetros de configuración disponibles directamente desde la fuente.
- Documentación del kernel: cgroup v2 — Para entender cómo los límites de memoria en contenedores interactúan con el OOM Killer y cómo interpretar las métricas de presión de memoria (
memory.pressure). - «Taming the OOM killer» — LWN.net (2009) — Sigue siendo la explicación más completa del algoritmo de puntuación publicada fuera del código fuente. Escrita cuando se rediseñó el algoritmo actual, todavía es válida para entender la lógica de fondo.
- «Understanding the Linux Kernel» — Bovet y Cesati, O’Reilly — Cubre hasta el kernel 2.6, así que no refleja cgroup v2 ni el comportamiento moderno, pero sigue siendo una referencia útil para los mecanismos internos fundamentales de gestión de memoria y swap.
man 5 proc— Para entender cada campo de/proc/<PID>/oom_score,/proc/meminfoy/proc/pressure/memorydirectamente desde tu sistema, sin salir de la terminal.