
En la práctica diaria de administrar sistemas, especialmente en entornos cloud y con infraestructuras dinámicas, el control de costes se ha convertido en un desafío tan importante como mantener la disponibilidad o la seguridad. Los equipos técnicos suelen enfrentarse a la paradoja de reducir gastos sin sacrificar la visibilidad necesaria para detectar problemas, diagnosticar fallos o anticipar incidentes.
FinOps, o la gestión financiera operativa en la nube, emerge como una disciplina que busca equilibrar eficiencia económica y operativa. Pero, ¿cómo puede un administrador o un equipo de SRE aplicar estos principios sin que la monitorización y la observabilidad se vean comprometidas? Este artículo ofrece un enfoque práctico para integrar FinOps en el día a día técnico, con consejos concretos que aportan valor real.
El lector aprenderá a identificar áreas donde el gasto se puede optimizar sin perder datos críticos, a implementar controles básicos y a comunicar resultados que faciliten la colaboración con finanzas y desarrollo.
El dilema clásico: coste vs. visibilidad
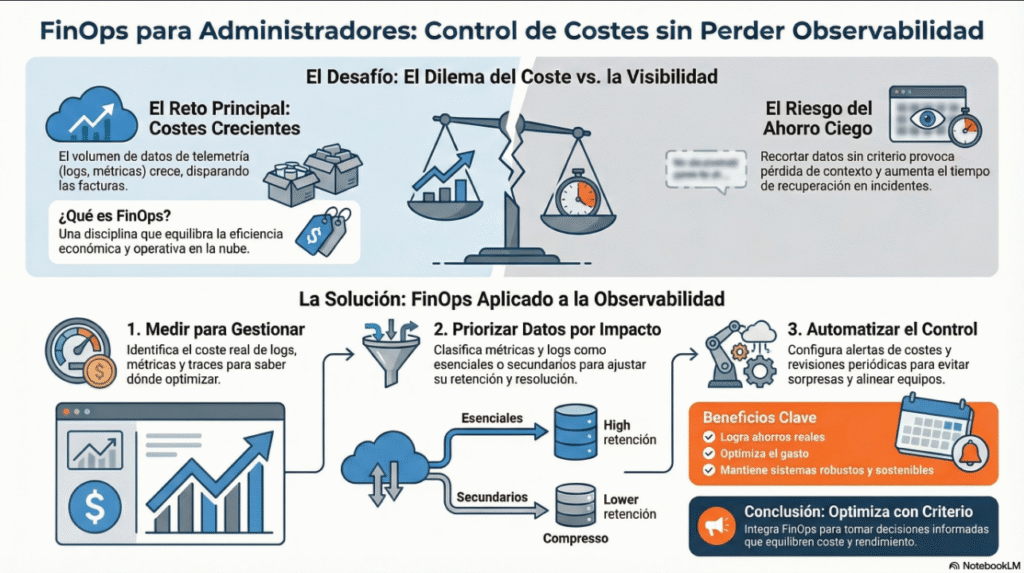
Tradicionalmente, la monitorización y la observabilidad se han considerado gastos fijos o incluso «costes invisibles» dentro de la infraestructura. Sin embargo, en entornos cloud donde se paga por uso, cada métrica, cada log almacenado o cada alerta configurada tiene un coste asociado. Es común encontrarse con situaciones donde el volumen de datos de telemetría crece exponencialmente, y con ello las facturas de almacenamiento y procesamiento.
Algunos equipos reaccionan recortando datos o espaciando sondeos para ahorrar, pero esto puede traducirse en pérdida de contexto durante incidentes, dificultando el diagnóstico y aumentando el tiempo de recuperación. La clave está en aplicar FinOps no como un recorte ciego, sino como un proceso continuo de optimización inteligente.
Principios FinOps aplicados a la observabilidad
1. Medir para gestionar: visibilidad del gasto en telemetría
El primer paso es obtener datos claros sobre cuánto cuesta realmente cada componente de la observabilidad. Esto incluye:
- Costes de almacenamiento de logs, métricas y traces.
- Costes de ingestión y procesamiento en herramientas SaaS o autogestionadas.
- Costes asociados a alertas y consultas frecuentes.
Conocer estos datos permite identificar qué fuentes de datos o qué tipos de métricas generan mayor coste y valorar si aportan suficiente valor. Por ejemplo, es habitual que ciertos logs de debug o métricas de alta cardinalidad no aporten insights relevantes y podrían reducirse o filtrarse.
2. Priorizar métricas y logs según impacto operativo
No todas las métricas o logs tienen el mismo valor para la resolución de problemas o para la prevención. Aplicar una clasificación basada en la criticidad ayuda a enfocar recursos:
- Métricas esenciales: aquellas que permiten detectar degradaciones o fallos críticos.
- Logs clave: eventos que aportan contexto relevante para incidentes.
- Datos secundarios: información útil para análisis a largo plazo pero que puede almacenarse con menor frecuencia o retención.
Por ejemplo, reducir la retención de logs de aplicaciones menos críticas o almacenar métricas de baja prioridad con menor resolución puede generar ahorros sin impacto operativo.
3. Automatizar alertas y revisiones de coste
Integrar alertas que avisen cuando los costes de observabilidad superen umbrales razonables es una práctica recomendada. Esto evita sorpresas y permite reaccionar a tiempo. Además, establecer revisiones periódicas con los equipos técnicos y financieros ayuda a alinear objetivos y a ajustar configuraciones.
En la práctica, esto puede incluir scripts que consulten APIs de coste de la nube o de las herramientas de observabilidad para generar reportes automáticos, o dashboards internos que muestren tendencias de gasto.
Ejemplo práctico: optimización de métricas en Prometheus
En sistemas basados en Prometheus, es común que la cardinalidad de métricas explote sin control, generando altos costes en almacenamiento y consulta. Un enfoque práctico incluye:
- Revisar etiquetas (labels) para eliminar o agrupar aquellas que no aportan valor real.
- Configurar reglas de grabación (recording rules) para preagregar datos y reducir consultas costosas.
- Aplicar retención de datos diferenciada según la criticidad de la métrica.
Por ejemplo, si una métrica tiene etiquetas con IDs únicos de usuario que no se usan para alertas, es mejor eliminarlas o anonimizar para evitar cardinalidad alta. Esto reduce el volumen de datos y mejora la eficiencia sin perder la capacidad de detectar problemas.
Evitar la trampa del “todo lo quiero medir”
La cultura de la observabilidad invita a tener visibilidad completa, pero esto no significa que todo sea igual de útil. En muchos casos, el exceso de datos genera ruido y costes innecesarios. FinOps invita a un enfoque más pragmático y selectivo, donde la monitorización se diseña pensando en el balance coste-beneficio.
Es habitual que equipos técnicos deban negociar con áreas de negocio o finanzas para justificar inversiones en observabilidad. Presentar métricas de coste y valor ayuda a tomar decisiones informadas y a evitar recortes arbitrarios que puedan afectar la estabilidad.
Takeaways para aplicar FinOps en observabilidad
- Conoce el coste real: monitoriza y analiza cuánto cuesta cada componente de tu sistema de observabilidad para identificar puntos de optimización.
- Clasifica y prioriza: no todos los datos son igual de valiosos; ajusta retenciones y resoluciones según impacto operativo.
- Automatiza revisiones: establece alertas y reportes periódicos para mantener el control y alinear equipos técnicos y financieros.
Conclusión
Integrar FinOps en la gestión de la observabilidad no es simplemente recortar gastos, sino hacerlo con conocimiento y criterio para mantener la capacidad de respuesta y diagnóstico. Los administradores y equipos SRE que adoptan esta mentalidad logran no solo optimizar costes, sino también fortalecer la colaboración entre áreas y mejorar la toma de decisiones.
El equilibrio entre visibilidad y coste es dinámico y requiere revisiones constantes, pero con prácticas claras y herramientas adecuadas es posible mantener sistemas robustos y económicamente sostenibles.
Para quien quiera profundizar en técnicas avanzadas de monitorización y observabilidad, en observasistemas.com hay contenido especializado que complementa este enfoque práctico con detalles técnicos y casos reales.
Si quieres ver este contendio en Youtube: https://youtu.be/fywvx-eoCT4?si=1Bq8Ox5eERcsxnZI